Creating a Summary PDF of Images
I often have to go on inspections for my job and when I do, I take up to 100 pictures. The client very rarely needs or wants the original image files, but they often want a copy of all of the images. Instead of sending the client 25 emails containing 4 images each or setting up a ShareFile, I wrote a Python script to copy all of the images to a single PDF.
Overview
When this script runs, a window pops up which prompts the user to select the folder that contains the images. 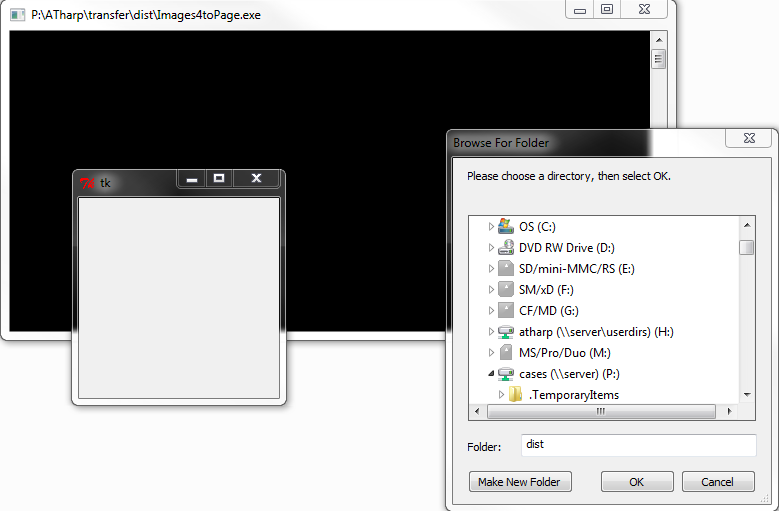 Once the directory is chosen, the script runs, copying each image and pasting the image into a page, 4 at a time. At the corner of each image, the script puts the file name. This way, when discussing the images with the client or coworker, we always have something to reference. Once a page is created, the page number is posted to the output window. This helps the user know the script is running. Once the script is finished, the window will display the total time it took to run and the average time per page.
Once the directory is chosen, the script runs, copying each image and pasting the image into a page, 4 at a time. At the corner of each image, the script puts the file name. This way, when discussing the images with the client or coworker, we always have something to reference. Once a page is created, the page number is posted to the output window. This helps the user know the script is running. Once the script is finished, the window will display the total time it took to run and the average time per page. 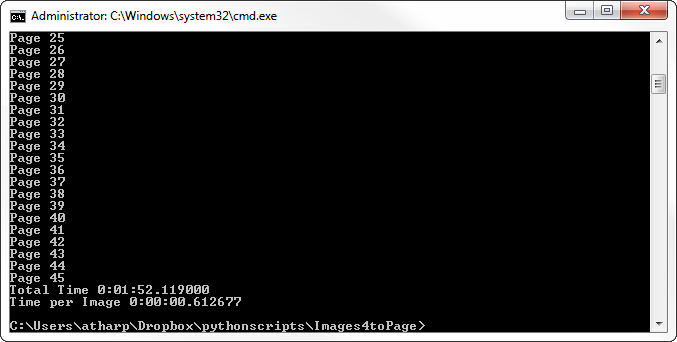 After it is completed, the PDF document is created called ‘document-out.pdf’. Below is an example of what the output looks like.
After it is completed, the PDF document is created called ‘document-out.pdf’. Below is an example of what the output looks like. 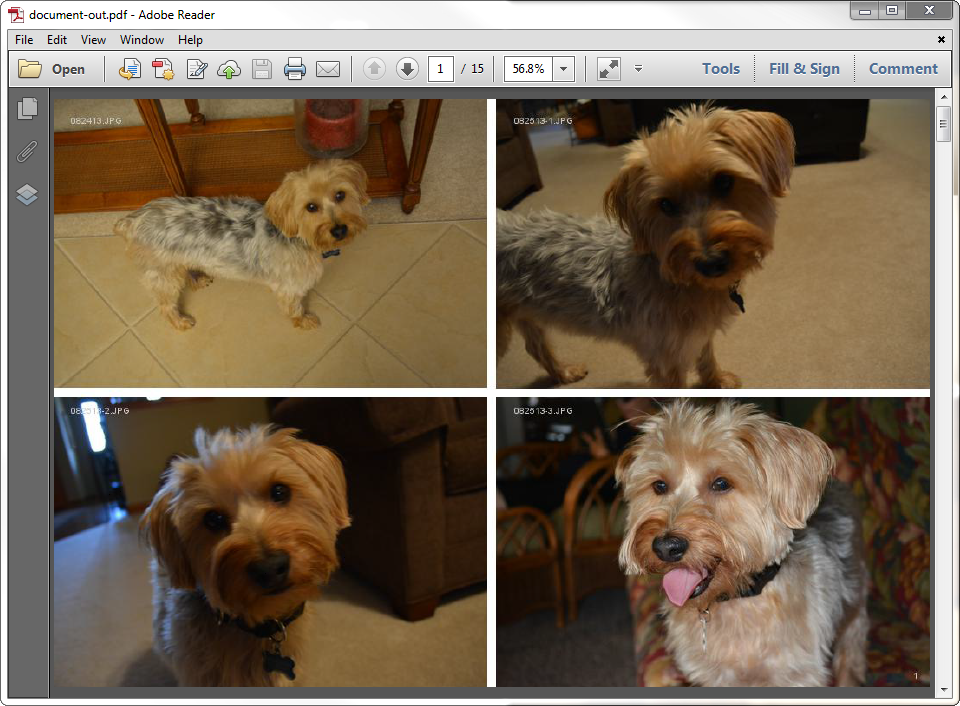
Code
The complete code can be found on my Gist here. As with any Python script, we first import the necessary libraries. [python] import glob from PIL import Image, ImageDraw, ImageFont, PdfImagePlugin, _imaging from math import ceil from pyPdf import PdfFileReader,PdfFileWriter import os from datetime import datetime import tkFileDialog [/python] In this case, we are using:
glob
- Used to create our pathname
PIL (Python Image Library)
- Used to manipulate the images
ceil function within math library
- Used to round up
pyPdf
- Used to read and write PDFs
os
- Used to get the image file names
datetime
- Used to count total time the script runs
tkFileDialog
- Used for the GUI dialog box
Next, we start the timer. This is not a necessary function for the script. However, I wrote this for work and wanted to show how much quicker it was to create the PDFs this way than it is to create them manually using Word (which is what my coworkers were doing at the time). The current time is saved into a variable startTime and will ultimately be used to calculate the total time. After this, we use tkFileDialog to open a GUI and allow the user to select the directory. We only care about JPG files, so we add “/.jpg” to the directory to get only the image files in that folder. [python] startTime = datetime.now() dirname = tkFileDialog.askdirectory() dirname = dirname + “/.jpg” filenames = glob.glob(dirname) [/python] The glob.glob(dirname) line creates a list of all of the file names (again, only the JPGs) in this folder and saves it to the variable filenames. Next, we count the number of images in this directory by taking the length of the filenames and we determine the number of pages by using the formula: [python] NuPages = int(ceil(float(NuImages)/4)) [/python] There are a few things going on here. First, we make the variable NuImages be a floating value. With Python, if you do not first define a value as floating, the quotient will always be an integer. I want to explicitly tell Python to round up, so I first make the variable be a floating value, divide it by 4 (since there are 4 images to a page) then wrap the quotient into a ceil function, which rounds up. Finally, I take this number and I make it an integer so I can use it later. Next, I check to see if ‘temp2.pdf’ already exists. If it does, I remove it. ‘temp2.pdf’ is used later as a blank pdf to paste all of the images in. Finally, I set up the variables for the size of each picture: [python] if os.path.isfile(‘temp2.pdf’): os.remove(‘temp2.pdf’) merged = PdfFileWriter() size = 500,500 width = 500 height = 500 count = 0; [/python] A large portion of this script takes place in the following for loop. This section of code loops for each page (so, from 0 to NuPages times). The first thing we do is print the page number to the output window so the user knows the script is still running. [python] print (“Page “ + str(pgnum)) w = [] h = [] [/python] For the four images on this page, we resize each of the images to 500x500 and save the widths and heights of each image into the variables w _and _h. Then, I find the max of each of these lists (this is a back up in case an image does not get resized. For instance, if an image starts off smaller than 500x500, it might not be enlarged to fit 500x500). [python] for num in range(0,4): if num+count < NuImages: im = Image.open(filenames[num+count]) im.thumbnail(size,Image.ANTIALIAS) width,height = im.size w.append(width) h.append(height) width = max(w) height = max(h) [/python] Next, I create the background. The trick here is that each page is actually 5 images: a background image and 4 pictures from the directory. The background image is simply a white picture that is twice as large as the biggest picture, plus 10 pixels in both directions to add a little bit of a separation between the images. [python] blank_image = Image.new(“RGB”,(width*2+10, height*2+10),”White”) draw = ImageDraw.Draw(blank_image) font = ImageFont.truetype(‘arial.ttf’,10) [/python] The next section adds the images to the page. The if statements that follow the general form: [python] if count + X <= NuImages: [/python] where x = [0,1,2,3] is used because the last page might have less than 4 images. The variable count is used to track the number of images already added from previous pages. These if statements go through and make sure that the image you are currently trying to add actually exists before attempting to add it. Within each of these if statements are the lines: [python] img = Image.open(filenames[count]) img.thumbnail(size,Image.ANTIALIAS) blank_image.paste(img,(0,0)) head, tail = os.path.split(filenames[count]) draw.text((20,20), tail,(200,200,200),font=font) [/python] The first part of this opens the image and resizes it. Next, it pastes the image into its location on the blank_image that we created as a background and adds the filename to the corner. The coordinates for this are all slightly different for each if statement so that everything is separated. Finally, the page number is written in the bottom corner of the image: [python] draw.text((2*width-10,2*height-10), str(pgnum+1),(200,200,200),font=font) [/python] Finally, the image is saved to the temporary pdf from before, ‘temp2.pdf’ and merged to the final output. [python] blank_image.save(“temp2.pdf”,”pdf”) pdf1 = open(“temp2.pdf”,”rb”) pdf = PdfFileReader(pdf1) for page in pdf.pages: merged.addPage(page) count = count+4 outputStream = file(“document-out.pdf”,”wb”) merged.write(outputStream) pdf1.close() [/python] This entire section is repeated for every page. Once each page has been created, the PDF file is closed and the total time is calculated by subtracting the startTime from the current time. In addition to this, the average time per image is printed to the output screen. [python] outputStream.close() print(“Total Time “ + str(datetime.now()-startTime)) print(“Time per Image “ + str(((datetime.now()-startTime))/NuImages)) [/python] That is pretty much it! I wrote this script several years ago, not long after I began learning Python. There are a few things I would do differently if I were to do this project now. For instance, I do not believe the portion where I check for the max width of each image is necessary, and I think the 4 if statements in the main loop could be made much more efficiently. Additionally, the script works best for images that are all oriented the same. It would be nice try to put all of the landscape images together and all of the portrait images together. However, the script works for what it does and has been a big time saver for me at work. If you have any questions or suggestions, please let me know in the comments or contact me!