How to Parse XML Data with Python From URL
I wrote a Python script to pull data from every board game on BoardGameGeek and put it into a SQLite database. It took four days for this script to run the first time. I was able to make it more efficient and ran it again but it still took over two days! I figured this could certainly go faster, so I decided to stop using the Python BGG XML API and instead learn a little bit about XML and how to parse the data myself. I was able to learn enough about XML and parsing the data to get a new script up and running in just a couple of hours. The script ran so fast that BoardGameGeek throttled me and eventually kicked me off for overloading the website. Using the XML directly meant that the script went so fast that I literally had to slow it down!
What is XML?
XML stands for Extensible Markup Language. A markup language is a way for writing a document such that the text is easily distinguishable from the formatting and other syntax. You have probably seen a markup language before. Some notable examples include HTML, XML, and TeX. XML is good because it is human-readable and machine-readable. It strives for simplicity, generality, and usability. An example of XML is shown in the image below. 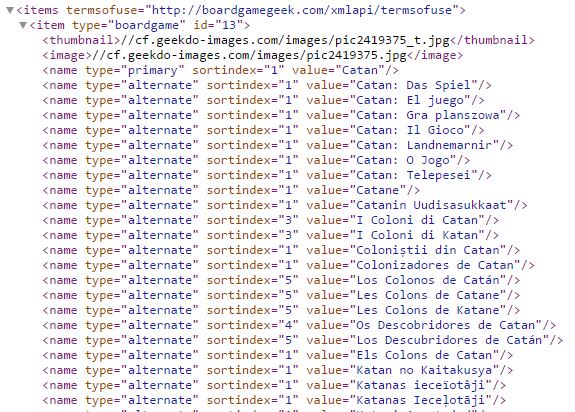 In order to easily work with XML, there are some definitions we’ll need to understand. First, XML is built with tags. A tag always begins with < and ends with >. There will be a start-tag which will look like
In order to easily work with XML, there are some definitions we’ll need to understand. First, XML is built with tags. A tag always begins with < and ends with >. There will be a start-tag which will look like
This entire line is the tag. The element is name and the attributes are type, sortindex, and value. Their values are “primary”, “1”, and “Catan”.
What is Parsing?
Think of parsing as translating one piece of data into another kind of data. When we talk about parsing XML, we mean that we want to take XML data like in the example image above and turn it into something useful, such as a database or even just printing out “This game’s name is: “ followed by the name (can you find it in the previous tag? It’s “Catan”!).
How Can We Parse XML With Python?
You can Parse XML data with many, many languages. I’m strongest with Python, so I was interested in learning how to do this with Python. Even within Python, there are more than one modules available for parsing XML data. For me, I chose to use the module xml.dom.
Find XML Data to Parse
I assume if you are here, you probably have some XML file or URL that you want to parse. If not, this is a good example and will be what I’ll be using for the tutorial.
Import Module And Connect
In Python, we want to import our module and connect to the URL. To do this, we will use:
# Import modules
from xml.dom import minidom
import urllib2
url = ‘https://www.boardgamegeek.com/xmlapi2/thing?id=13&stats=1' # define XML location
dom = minidom.parse(urllib2.urlopen(url)) # parse the data
Here, we are importing the XML module xml.dom and the URL module urllib2. The XML module will be used for dealing with the data and the URL module is so that we can open the URL. Alternatively, you may have the XML saved in a .XML file. If this is the case, you’ll need to open the file instead of opening the URL.
Find A Tag You Are Interested In
Looking at the XML URL from our example, I am interested in grabbing the number of owners of this game. I used ctrl-f and searched for “own” to find the following line:  Here, you can see the tag is
Here, you can see the tag is
I’m only interested in the value (80966). It doesn’t matter that this tag is nested within ranks (which is itself nested within ratings which is nested within statistics). To grab this value, we’ll use the Python lines:
owned = dom.getElementsByTagName(‘owned’)
owned = int(owned[0].attributes[‘value’].value
The first line grabs an XML object, which doesn’t do us much good. The second line grabs the value for the first item in the XML object (notice in the image that there is only one) then converts it to an integer (from Unicode).
What If There Are Multiple Tags With The Same Name?
Sometimes, the XML data might have many tags with the same name and you want to grab only specific ones. Below is an example of this. Here, there are many tags with the name link. However, I only care about the category (“Negotation”). If we use the lines from above, we may or may not get the correct thing (if this is the first item, it would be correct. Otherwise, we’ll be grabbing the wrong data!). To do this, we’ll use the following Python code:
Here, there are many tags with the name link. However, I only care about the category (“Negotation”). If we use the lines from above, we may or may not get the correct thing (if this is the first item, it would be correct. Otherwise, we’ll be grabbing the wrong data!). To do this, we’ll use the following Python code:
link = dom.getElementsByTagName(‘link’)
categories = [items.attributes[‘value’].value for items in link if items.attributes[‘type’].value == “boardgamecategory”]
The first line is the same. We are grabbing all of the XML objects that have the tag name link. The problem is that there are a lot of them! Notice that the attributes in this tag are type, id, and value. The second line is a Python list comprehension for a for loop which loops through all of the XML objects with the tag name ‘link’ and looks for only the ones that have the attribute type equal to “boardgamecategory”. Another way to write this would be:
link = dom.getElementsByTagName(‘link’)
categories = [items.attributes[‘value’].value for items in link if items.attributes[‘type’].value == “boardgamecategory”]
for items in link:
if items.attributes[‘type’].value == “boardgamecategory”:
return items.attributes[‘value’].value
That’s it. When I first tried to tackle this topic, I found it a little confusing. I thought that if a tag was nested into another tag (like the example above with owned) that I would need to do something with the tags above it. At least with this module, we don’t have to worry about that. It’s really easy – in fact, using this may be easier than using the Python BGG wrapper that I was using before. Have questions or suggestions? Please feel free to comment below or contact me.