Board Game Geek Database Followup
A couple of months ago, I made a Python script and SQLite database to pull data from Board Game Geek (BGG). I wrote a blog post on the database here and a different one on how I pulled the data using BGG’s XML API here. I also started a Twitter account, @BGGstats, where I post cool things I’ve found with the data. The database and script have both grown and I’ve learned a couple of neat tricks for querying data so I thought it would be a good time to follow up.
The Database
The new database schema looks like this:  I added: artists, publishers, designers, categories, families as well as the rank, weight, number of users trading, wishing, and wanting, the average rating, bgg rating, and number of users voting for the rating.
I added: artists, publishers, designers, categories, families as well as the rank, weight, number of users trading, wishing, and wanting, the average rating, bgg rating, and number of users voting for the rating.
The Script
The new script is available on my Gist, here. The new script handles all of the new tables and columns that were added to the database. In addition, it handles errors a lot more efficiently. Before, I wasn’t really checking for any errors. Now, I try to check for some common errors. In general, the script will error out because I’ve been throttled by BGG or my internet or BGG is down. This generally shows itself as an HTTPError, so that is what I check for. If I encounter that error, I log it to a text file along with the ID of the game that it errored out on. I then wait 10 seconds and try again. If it doesn’t work, I skip the ID. This lets me run the script without having to worry about checking in on it to make sure it is still running. I run this script at midnight on the first of every month. For each game, it adds new entries for all of the information in the collection table and it also looks for new games.
To Do
There are a few things I want to add to the script:
- I’d like to write the line number that the script errors out on into the text file.
- Sometimes BGGIDs will be removed from BGG. This could happen for a few reasons, the most common is probably someone adding a new entry for a game that already exists. Sometimes, I might grab this BGGID while it still exists (before it gets removed). If I find that a BGGID has been removed, I want to handle that somehow in my database. In the end, it is likely duplicate information and would probably be removed from the database. However, if I could just generate a list of these IDs so that I can check them myself, that would be good.
- The script already checks to see if the games and collection tables exist (and if they don’t, it creates them). I need to add this functionality to all fourteen tables.
- I’d like to add the ability to track the total number of plays per game. This isn’t available in the XML API, but I should be able to pull it directly from the website.
I’m sure my to do list will continue to evolve as the project grows. Each of these items is definitely doable and I think they would all be value added to the project, so I’m exited to get them going.
Results
If you follow me on Twitter, this will be old news. Below are some of the more interesting plots and stats that I’ve found through working with the data (all of the charts were generated using Python’s Matplotlib library and the data I collected using the above method): 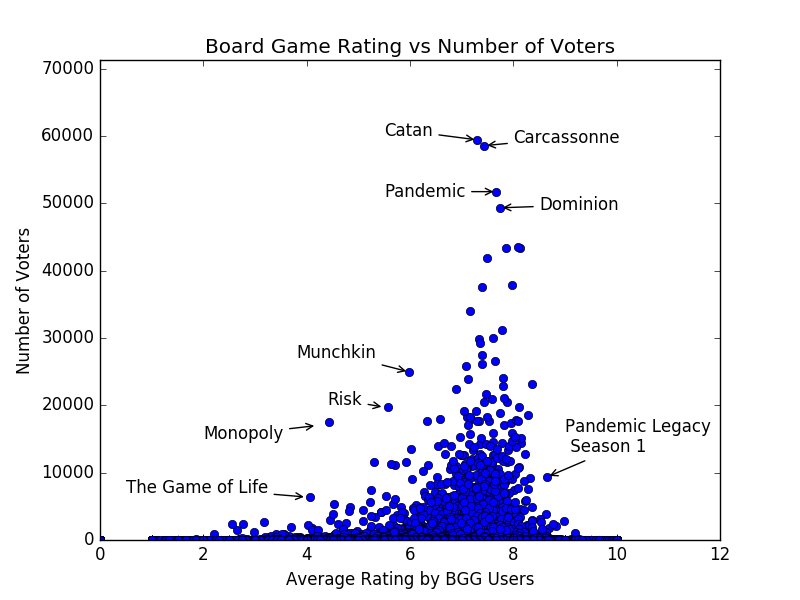
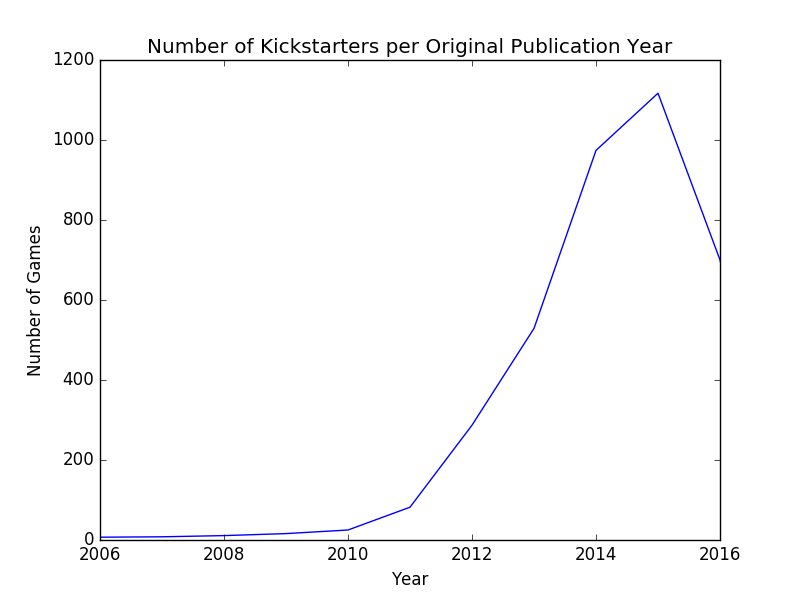 Finally, one of the more surprising things I found (surprising as in I wasn’t looking for it or expecting to see anything like this in the data): The most common first name for artist sin the top 100 is Richard.
Finally, one of the more surprising things I found (surprising as in I wasn’t looking for it or expecting to see anything like this in the data): The most common first name for artist sin the top 100 is Richard.
Query Explanation
The thing that I was most interested in when I started this project was to see how things change on a monthly basis, such as which game increase the most in rank from one month to the next (in BGG terms, increasing rank means getting closer to number 1, which is a good thing). Figuring out this query was pretty difficult, so I thought I’d share it here. First, the query:
SELECT games.bggid, games.name, diff FROM ( select
rowid,
(SELECT MIN(tt.rowid) FROM collection AS tt WHERE tt.rowid > collection.rowid AND tt.bggid = collection.bggid) AS next_rowid,
(SELECT rank
FROM collection AS t3 WHERE t3.rowid =
(SELECT MIN(tt.rowid) FROM collection AS tt WHERE tt.rowid > collection.rowid AND tt.bggid = collection.bggid)
) AS next_rank,
(SELECT rank FROM collection AS t3 WHERE t3.rowid =
(SELECT MIN(tt.rowid) FROM collection AS tt WHERE tt.rowid > collection.rowid AND tt.bggid = collection.bggid)
) - rank AS diff,
collection.bggid as id
FROM collection
where diff > -10000 AND collection.date >= ‘2016-06-01’)
inner join games on games.bggid = id
order by diff asc limit 10;
First, not all of this is necessary. However, having all of it will help us see what is going on. This is my most intense query as there is a query in a query in a query in a query! The outer most query is essentially:
SELECT games.bggid, games.name, diff FROM (
—OTHER QUERIES—
)
INNER JOIN games ON games.bggid = id
ORDER BY diff ASC LIMIT 10;
Other than the crazy OTHER QUERIES inside of this, it is pretty straight forward. The outer most query is select specific things from the inner queries and will ultimately be what gets printed in the command prompt. The next query is this:
select
rowid,
(SELECT MIN(tt.rowid) FROM collection AS tt WHERE tt.rowid > collection.rowid AND tt.bggid = collection.bggid) AS next_rowid,
rank,
(SELECT rank FROM collection AS t3 WHERE t3.rowid =
(SELECT MIN(tt.rowid) FROM collection AS tt WHERE tt.rowid > collection.rowid AND tt.bggid = collection.bggid)
) AS next_rank,
(SELECT rank FROM collection AS t3 WHERE t3.rowid =
(SELECT MIN(tt.rowid) FROM collection AS tt WHERE tt.rowid > collection.rowid AND tt.bggid = collection.bggid)
) - rank AS diff,
collection.bggid as id
FROM collection
where diff > -10000 AND collection.date >= ‘2016-06-01’
I’ve tried to indent the nested queries to make it easier to read. Here, we are selecting the rowid (this is a built in function to SQLite and selects just what it sounds like - the ID of the row you are currently looking at). Selecting this isn’t strictly necessary, but it can be helpful to visualize and understand. The next line selects the next row id. The next row id is wherever the next row is in the collection table for the same game but the following month. Within this nested select, we are looking for the smallest row id that is bigger than our current row id (so, the next row id) but that is for the same game (the same bggid). This gets selected and named as next_rowid. Again, this isn’t strictly necessary, but it is nice to go ahead and select is to that we can visualize this in the output if we want. Next, we simply select the rank of the current game. This is the rank that is associated with the rowid and not the next_rowid. _Again, this is not necessary to do but can be helpful. Now, we want to select the rank associated with the _next_rowid. To do that, we select the rank where the row id is equal to the next row id. Since this is all within the same query, we can’t simply call out next_rowid (though we could call that variable out in the outermost query). Therefore, we have to copy and paste that query after the equal sign. This is another reason why doing the queries separately can be helpful. However, again, doing this is not strictly necessary. Finally, we want to select what we are actually interested in: the difference between the next rank and the current rank (so, the difference between this month’s rank and last month’s rank). To do this, we simply copy the query for next_rank and subtract rank from it. We name it as diff. This one is necessary! That is pretty much it. I found a query similar to this online and adapted it to my own data. It took me a little while to understand it, but I’m now able to modify it for many different queries. I would like to develop a query very similar to this that checks to see the artist, designer, publisher, mechanic, etc that sees the greatest increase in the number of games in the top 1,000 from month to month. The query is a bit more difficult than the one shown here, so I don’t quite have it figured out yet. Have questions or suggestions? Please feel free to comment below or contact me.